Looker Studioのカスタムクエリを活用することでBigQueryに蓄積されたGA4やSearch ConsoleのデータをSQLベースで取得することが可能になる。この技術的なノウハウについて書かれた記事がないのと、あったとしても間違った情報が検索上位に上がっていたりするので、わざわざ解説することにした。詳細事項まで踏み込むとコンテンツが長くなるのでまずは最小限に留めた形で解説する。情報量が多くなるので都度コンテンツは追記予定。
≫ Google BigQuery に接続する > カスタムクエリ - Looker Studioのヘルプ
最初に結論を提示すると、カスタムクエリに記載するSQLは常に以下の1行が正しい
SELECT * FROM データマートテーブル名
Contents
なぜSELECT * が正しいのか?
少ないながらもLooker Studioのカスタムクエリの解説記事において、よく見かけるのがカスタムクエリの中に長たらしいSQLを書いて抽出をしている事例があるが、多くのデメリットを抱えているため強く非推奨というのが当記事の述べるところである。
まずその前に技術的背景について解説すると、「カスタムクエリ」とはまだ活用される背景自体が歴史がある分野ではなく、さらに特定のLooker StudioなどのBIツールとの組み合わせというスキルの掛け合わせを考慮する必要があるのが背景としてある。そのためベストプラクティスから外れた情報が出回ってしまうものだと推測できるが、このように「カスタムクエリ」単体だけでみた取扱いをすると、Looker Studioの特性を考慮しない形でデータの取得が行われるため、結果として非効率なデータ抽出が行われることになる。
以下、なぜカスタムクエリに長いSQL文を記載してはいけないのか、理由について列挙する
一般的にデータレイクテーブルには直接アクセスしない
カスタムクエリだけの機能だけを理解すれば、そこにSQLを記載すればデータが抽出できるのだから、取り出したいSQLをカスタムクエリに記載してGA4なりSearch Consoleのデータを取得すればいいと考えてしまいがちだが、通常BigQueryのようなデータウェアハウスに貯められたデータのような、何も整形が加えられていないデータには直接アクセスしないのが普通である。つまりテーブルぞれ自体に役割があるため、データを蓄積する役割を持ったテーブルに、分析用途としての役割まで付与しないのが、一般的なデータベースの設計となる。
分析料金が跳ね上がる危険性がある
この点がまさにLooker Studioとの組み合わせだから起こりえる問題ともいえるが、Looker Studioでレポートを作成すると、単純にカスタムクエリで記載した分析料金だけで済まないというか、確実に済まなくなる。というのも、Looker Studio上で何か日付を1日ずらすだけでも、都度カスタムクエリに記載したSQLの処理が走る。そのため、複雑なSQLで1回の処理で数GBの実行容量がかかるのであれば、毎回数GBの処理が走ることになる。BigQueryのデータを分析するSQLのことを「分析SQL」といったりするが、複雑な分析SQLになるほどにSQLの実行容量が大きくなる。またLooker Studioで配置するオブジェクト数が多く、クロスフィルタリングを掛け合わせると1回のレポート表示で数テラバイトを超えてしまうことも普通に起こり得る。このような場合、クエリ量の上限を設定していなければ制限なしにデータ容量を喰ってしまい後から、ビックリするくらいの料金がかかってしまうことがあるので、かなり注意が必要になる。例えば、単純な計算例でどれくらい分析容量が変わるのか。1回のSQL処理で必要になるデータ容量とLooker Studioで配置している各オブジェクトを掛け合わせてみる。
➀ 450MB = 30MB x 15オブジェクト
➁ 22.5GB = 1.5GB x 15オブジェクト
このようにLooker Studioでデータを可視化することで、最終的なデータ容量がたった1回レポートを表示するだけで、数十GBのデータが消費されるレポートが生成される。ではどうすればよいかはもうお分かりだと思うが、なるべく元データの容量を少なくすることが答えになる。この方法については後述する。
レスポンスが遅くなる
長く複雑なSQLになればなるほど、BigQueryであれそれなりに体験できるレベルで処理時間が長くなる。BigQueryからデータを抽出することでレポートの表示時間を短縮させられるメリットが、逆に直接GA4とAPI連携して接続するのと大して変わらないくらいの返答時間になってしまうこともあるのだ。これも同様の解決策としてはデータ抽出元となるテーブルに対して、「SELECT *」だけで済むテーブルを作成しておくこととなる。
大元のデータを破壊してしまうリスク
分析SQLではSELECT文しか扱わないため大元のデータにアクセスしてもデータを書き換えてしまったり、最悪削除してしまう可能性はかなり低いといえるが、必ずしも100%安全とも言い切れない。特に関係者が多くなるとこの辺のガバナンスも考えなくてはいけなくなるが、まずは最大の事故となり得る可能性を排除しておくべきだろう。仮に何年も蓄積したGA4のエクスポートデータが消えるとなるとかなり面倒なことになるので、データレイク的な純データに直接アクセスして分析・モニタリングレポートを作成するということはまず止めた方がよいだろう。
もしくはBigQueryのテーブルを選択する
カスタムクエリで生成したSQL文 「SELECT * FROM データマートテーブル名」 は結局のところテーブルを全て取り出す処理なのでテーブルを選択する方法と同じことになる。そのため、データマートテーブルを作成した後はそのテーブルを選択する方法をとってもよい。
A:Looker StudioからBigQueryでクリエイトされたテーブルにアクセスする際、カスタムクエリを使用してSQLを記述して読み込む場合と、BigQueryのテーブルを読み込む場合は、基本的には同じデータを取得することができます。具体的には、以下の2つの方法でデータにアクセスできます:
1. Looker Studioのカスタムクエリを使用: Looker Studioのカスタムクエリを使用して、任意のSQLクエリを記述し、BigQueryのテーブルからデータを取得できます。この場合、SQLクエリを自由にカスタマイズできます。例えば、特定のカラムを選択したり、フィルタリング条件を追加したりできます。
2. BigQueryのテーブルを読み込む: Looker Studio内で直接BigQueryのテーブルを選択し、そのテーブルからデータを読み込むこともできます。この場合、Looker Studioはテーブル名を指定するSQLクエリを生成し、テーブルのデータを取得します。一般的には、テーブル名を指定しない場合、`SELECT * FROM テーブル名` の形式のSQLクエリが生成されます。
要するに、Looker Studioを使用してBigQueryのテーブルにアクセスする場合、カスタムクエリを使用するか、直接テーブルを選択してデータを読み込むかは、データ取得の方法に影響しません。どちらの方法を選択しても、同じデータが取得されます。選択肢は、使用ケースや好みに応じて選ぶことができます。ChatGPT
参考: Google BigQuery に接続する -Looker Studioのヘルプ
データマートテーブルを間に挟みデータを抽出する
BigQueryのコスト削減について調査を進めても、なぜか「データマートテーブルの作成」について言及していることが少なく、このアドバイスに辿り着くことが難しかったりするが、コスト削減についてはまずはここから着手してみて、さらにクエリコストの見直しを図りたい場合は、まだ方法はあるので他の手段を試していくのが最適解だと私は考えている。
「データマート」とは用途に特化したテーブルのことを指し、逆に言えば必要としないデータが入っていないテーブルといっていい。そのようなデータマートテーブルは必然的にデータ容量が少なくなり、既にただ抽出すればよい状態まで整形を済ませ、「SELECT *」で抽出すればよい形まで予めテーブルを作り込み用意しておく。つまり、Looker Studioのカスタムクエリの中でごちゃごちゃSQLを記載するのではなく、これらの処理をBigQueryで済ましておくということ。
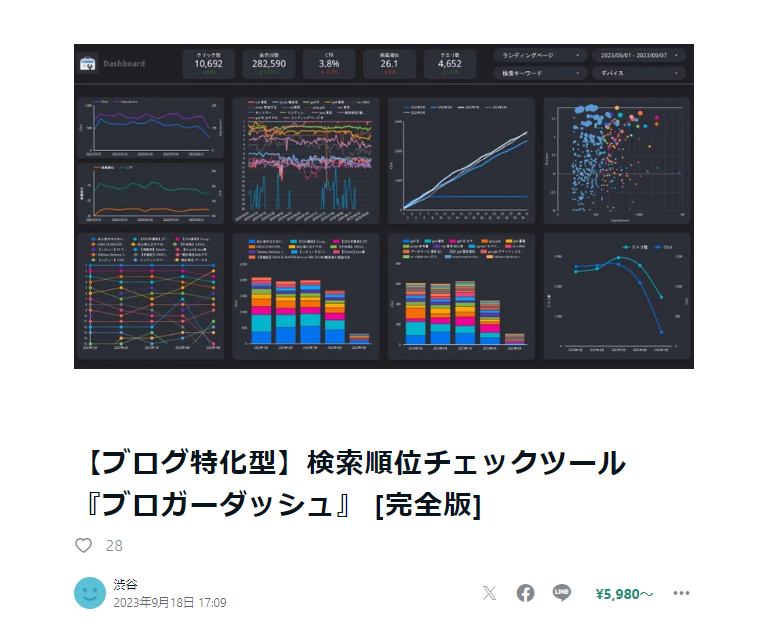
例えば、このレポートは私が作成したLooker Studioで動作する検索順位チェックツールであるが、1回のSQLで消費するクエリ量は数GBとなる。SQLのステップ数が300近く、またクロスフィルタリングが働くため、多くのクエリ量を消費してしまう。これを回避するためには、予めこのレポートを表示させるために必要な計算済みのカラムだけで構成されたデータマートテーブルを用意し、そこにアクセスすることでクエリコスト・レスポンスの応答まで解決することができる。
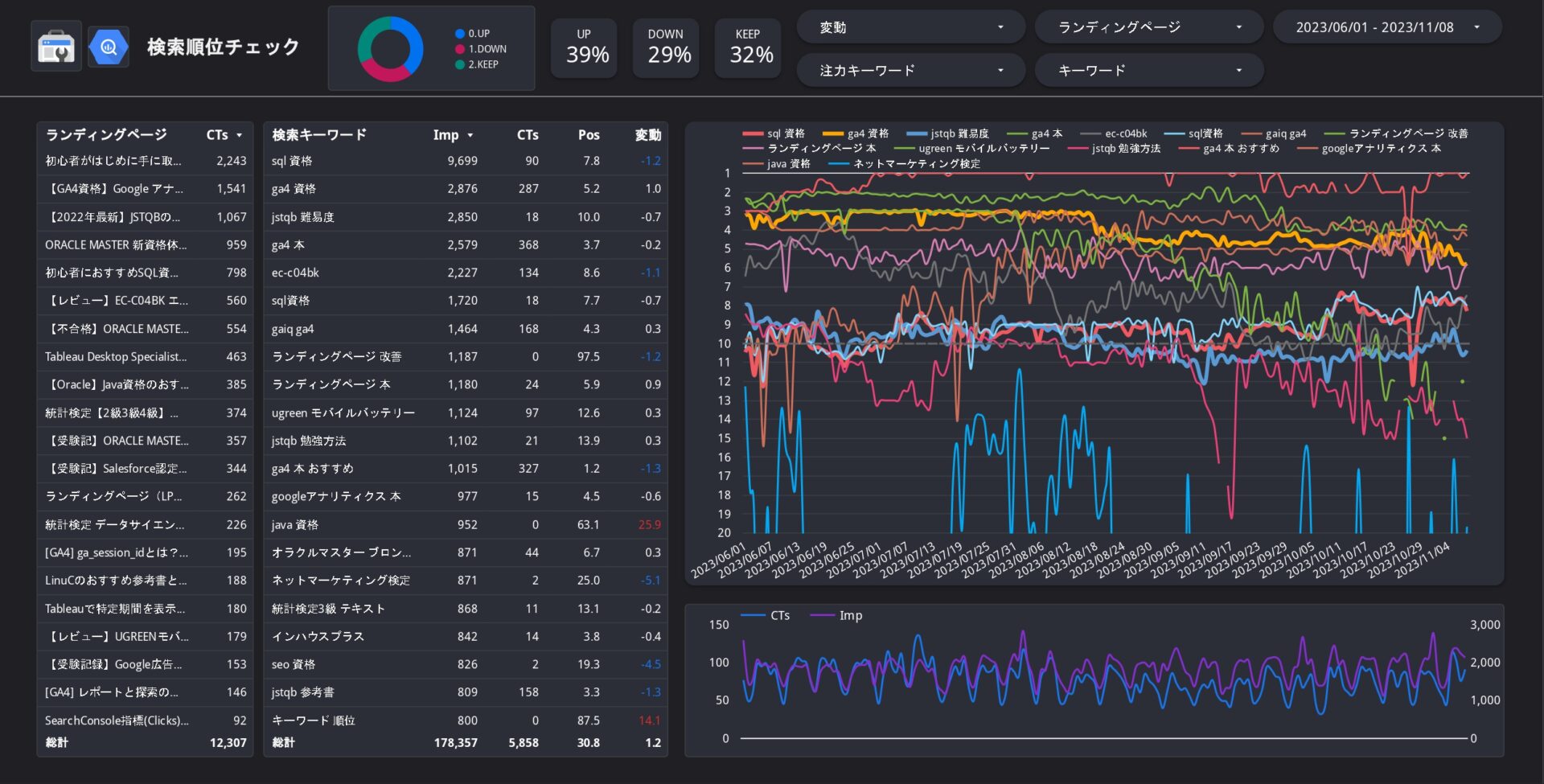
クエリのスケジューリングでデータマート作成
ではデータマートテーブルはどのように作成すればよいのかというと、BigQueryの「クエリのスケジューリング」機能を活用する。クエリのスケジューリングとは簡単に言えば、指定した時刻に指定したSQLを実行する機能。つまり、データマートテーブルは最新のデータまでが格納されたデータが必要であることがほとんどなので、ただ単にテーブルを作成するだけでなく、日付を指定することで常に最新のテーブルを用意することが可能となる。最新のデータマートテーブルはテーブルまるごと更新しなおしても良いし、1日分の差分を追加していく方法も取れるが、そこらへんは状況による。
データセットの作成
データマートを作成するにあたり、テーブルの格納先となるデータセットを作成する。データセットIDにデータセット名称を入力し"analytics_sql" など分析用途のSQLの格納先だと分かるような名称など自由に決めてよい。
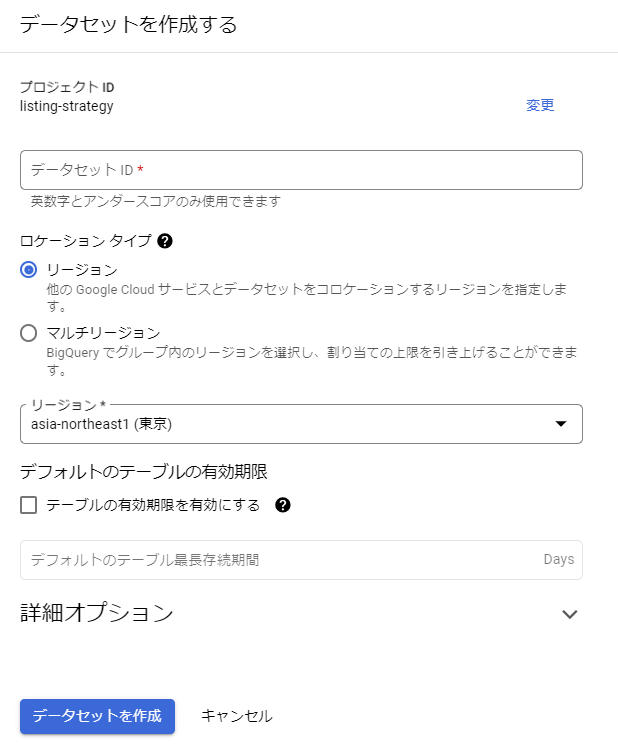
≫ データセットの作成 -Google Cloud BigQuery 公式ドキュメント
クエリのスケジューリング
作成したデータセットを指定し、その中にクエリのスケジューリングで指定したスケジュールでテーブルを更新/追加していく。今回はデータ容量的に差分で追加していくよりも、日次でテーブルをまるごと新規で上書きしていく方法を取る。Table IDは実質テーブル名称となるもので、今回はテーブルがまだ存在しない状態から、テーブル名を指定する。例えば"ranking_position"など。「宛先フィールドのパーティショニング フィールド」とはテーブルを最適化する機能で指定するとクエリ容量を削減できるため指定している。当レポートでは"_data_date_00"フィールドが該当する。
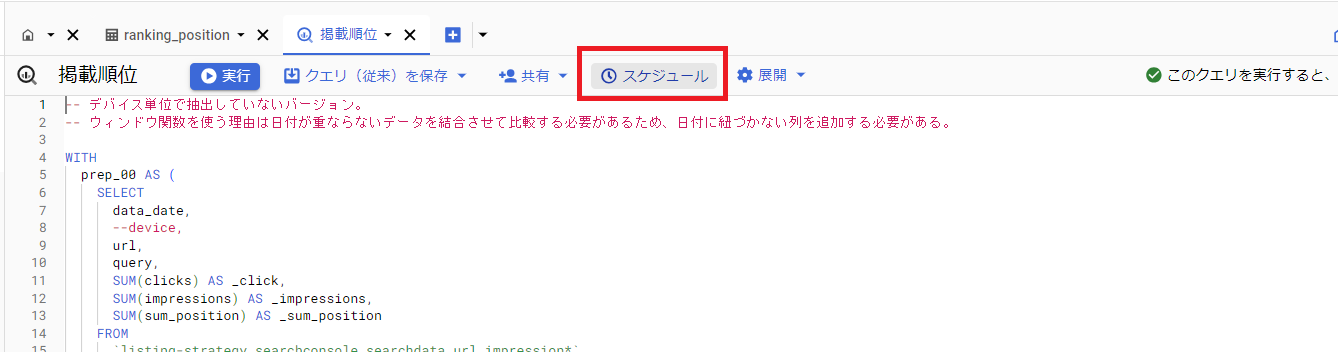
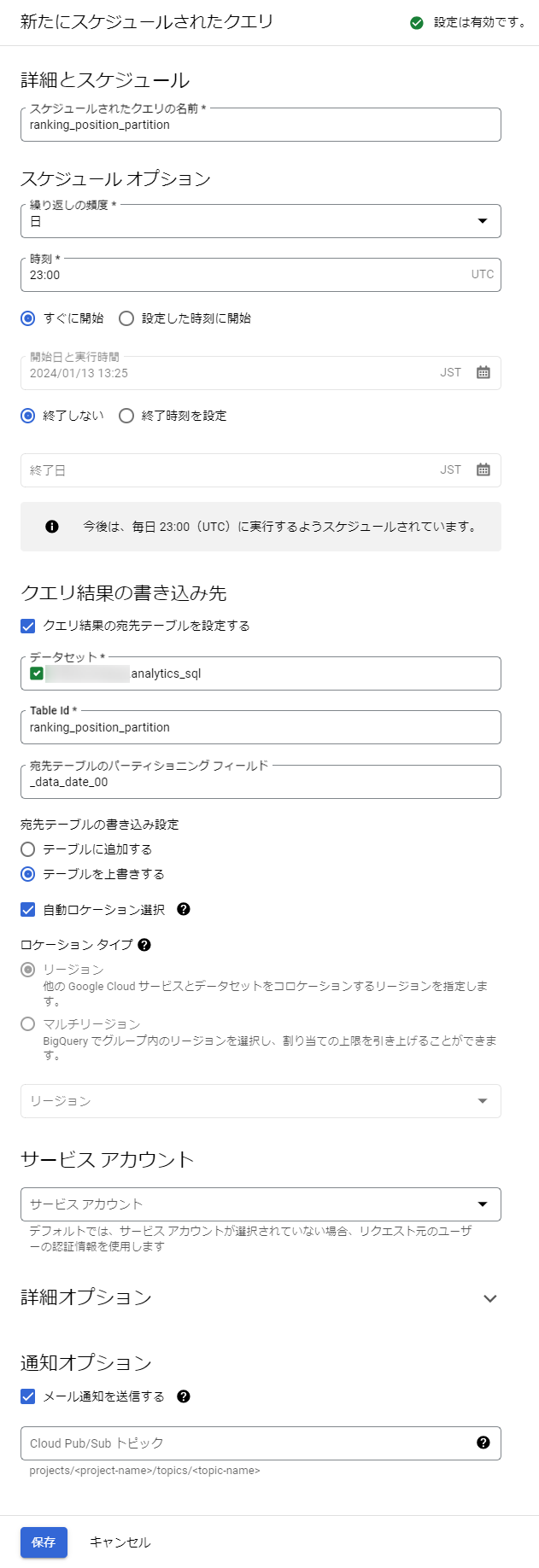
≫ クエリのスケジューリング - Google Cloudドキュメント
≫ パーティション分割テーブルの概要 -Google Cloud BigQuery 公式ドキュメント